Итоговые данные модели, определяются ее структурой. Они доступны к предпросмотру в карточке модели, но для использования модели в виджетах и информационных панелях данные модели необходимо загрузить в хранилище Системы. Загрузка может быть запущена как вручную, так и по расписанию (регулярное обновление).
Для проверки загрузки данных в модель нажмите на кнопку «Посмотреть загрузку в
Airflow» ( ) (см. 6, Рисунок «Окно
модели в режиме редактирования»). В новом окне web-браузера откроется
интерфейс Apache Airflow с деталями этого процесса (Рисунок «Окно Apache Airflow с информацией о
деталях процесса»).
) (см. 6, Рисунок «Окно
модели в режиме редактирования»). В новом окне web-браузера откроется
интерфейс Apache Airflow с деталями этого процесса (Рисунок «Окно Apache Airflow с информацией о
деталях процесса»).
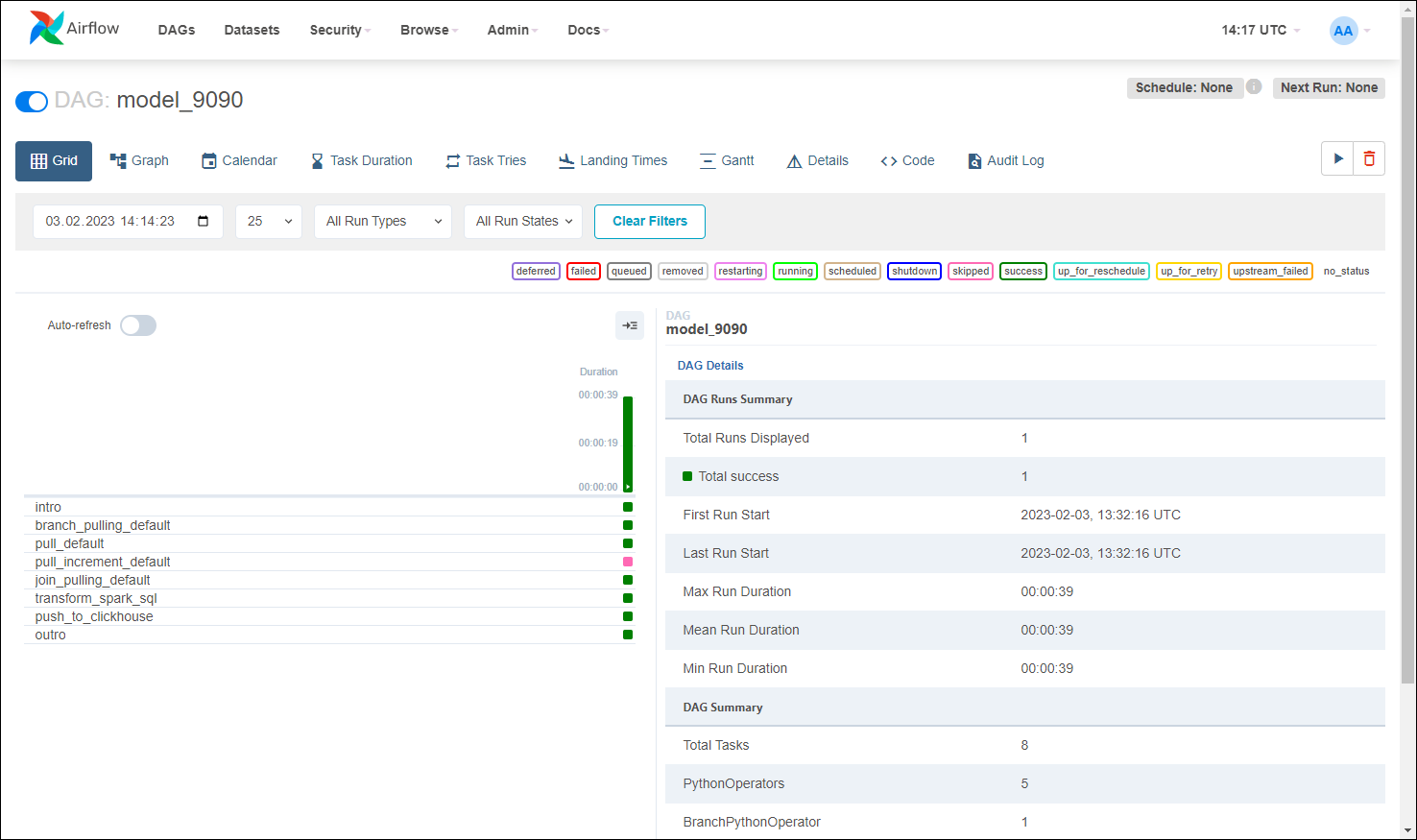
Если доступа на просмотр модели нет, то вместо дерева шагов откроется окно с сообщением: «У вас нет прав на просмотр модели с id <ID модели>. Вернуться назад».
Процесс загрузки заключается в сборе данных из различных источников, преобразовании данных в соответствии с бизнес-правилами и загрузке их в целевое хранилище данных. В качестве хранилища Системы выступает БД ClickHouse (или кластер ClickHouse), в котором построчные данные хранятся в виде столбцов и предоставляется оптимизированная индексация.
Каждый новый успешный процесс загрузки данных создает новую таблицу в хранилище и удаляет самую старую версию согласно параметру MODEL_SYNC_COUNT (количество хранимых версий). За счет версионирования происходит присвоение уникальных имен каждой версии модели.
Для работы с динамически изменяющимися таблицами из внутреннего хранилища Системы реализована функциональность по созданию представлений (view), что позволяет использовать в сторонних системах ClickHouse Системы как источник данных.
Запустить загрузку (или обновить) данных модели в аналитическое хранилище
вручную можно из интерфейса просмотра или редактирования модели. Для этого
нажмите на кнопку  на панели кнопок (см. 2, Рисунок «Окно модели в режиме
редактирования»). В нижнем левом углу окна будут отображаться
уведомления о ходе процесса (Рисунок
«Уведомление о начале загрузки», Рисунок «Уведомление о завершении
синхронизации»).
на панели кнопок (см. 2, Рисунок «Окно модели в режиме
редактирования»). В нижнем левом углу окна будут отображаться
уведомления о ходе процесса (Рисунок
«Уведомление о начале загрузки», Рисунок «Уведомление о завершении
синхронизации»).


Настройка регулярного обновления данных модели по расписанию выполняется
из интерфейса редактирования модели, через меню настройки модели. Для
выполнения настройки нажмите на кнопку перехода к настройкам модели  (Рисунок «Кнопка для
перехода к настройкам модели»).
(Рисунок «Кнопка для
перехода к настройкам модели»).
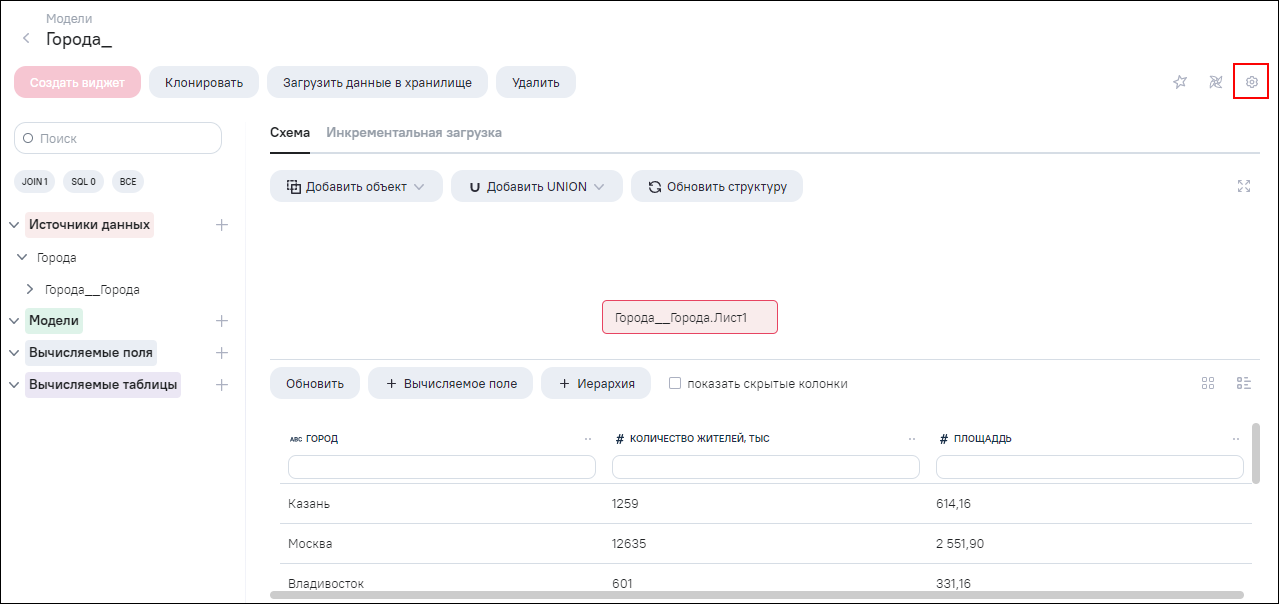
В окне «Настройки» перейдите в раздел «Планировщик».
Доступно два варианта настройки обновления данных модели по планировщику:
-
«На основе времени» (установлено по умолчанию) – принимает параметр на основе фиксированного расписания (Рисунок «Раздел «Планировщик», вариант настройки «На основе времени», п. Настройка загрузки (обновления) данных на основе времени);
-
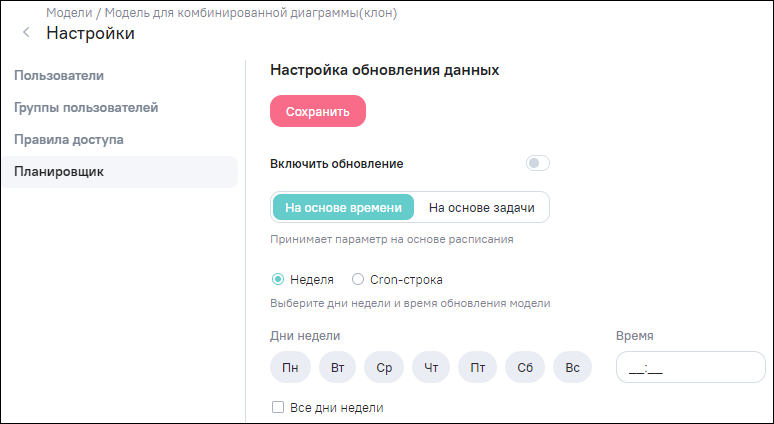
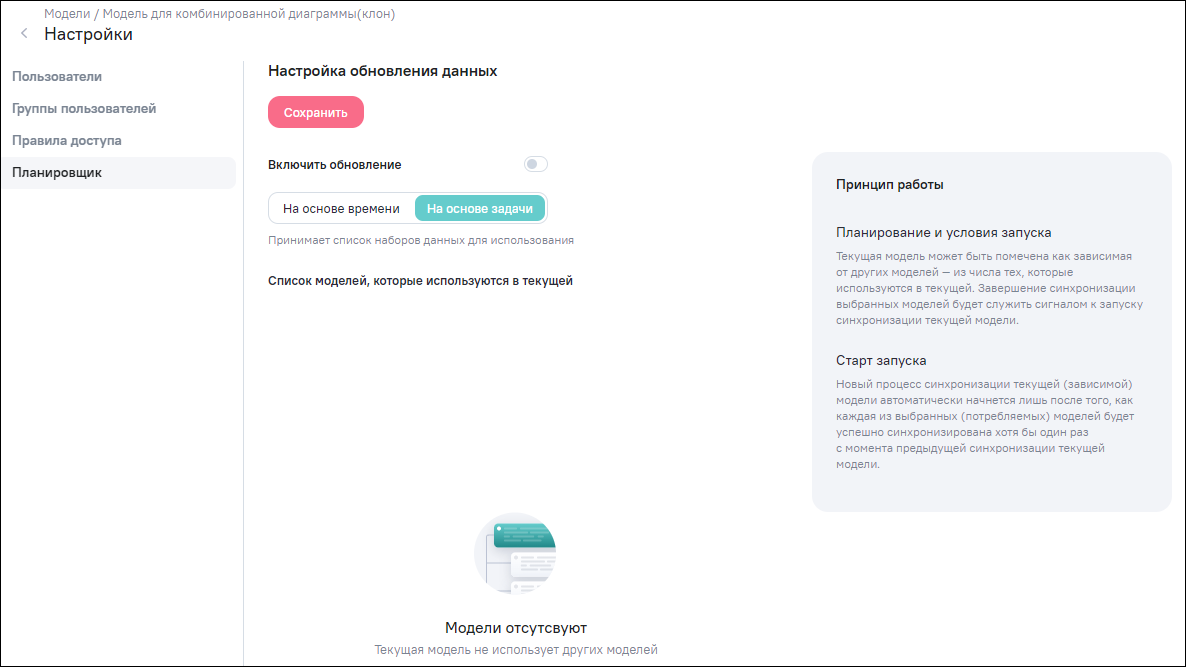
«На основе задачи» – принимает список наборов данных (моделей), завершение синхронизации выбранных моделей будет служить сигналом к запуску синхронизации текущей модели (Рисунок «Раздел «Планировщик», вариант настройки «На основе задачи», п. Настройка загрузки (обновления) данных на основе задачи).
Переключатель «Включить обновление» позволяет включить или отключить (не удаляя само расписание) настроенную задачу регулярного обновления данных.
Планировщик на основе времени можно настроить в одном из режимов (см. Рисунок «Раздел «Планировщик», вариант настройки «На основе времени»):
-
«Неделя»;
-
«Cron–строка».
Настройки планировщика по времени (режим «Неделя») позволяют создать обновление с периодичностью не чаще 1 раза в день и не реже 1 раза в неделю. Можно выбрать конкретный день (или дни) недели и указать с точностью до минуты (по времени сервера) время старта процесса обновления.
Для настройки расписания в режиме «Неделя» выберите день (дни) недели или установите «флажок» в поле «Все дни недели», чтобы выбрать все дни недели, и укажите время. Поля для выбора дней недели и времени являются обязательными для заполнения. Если данные поля не заполнены, то при сохранении откроется уведомление об ошибке. Чтобы сохранить и применить изменения, нажмите на кнопку «Сохранить».
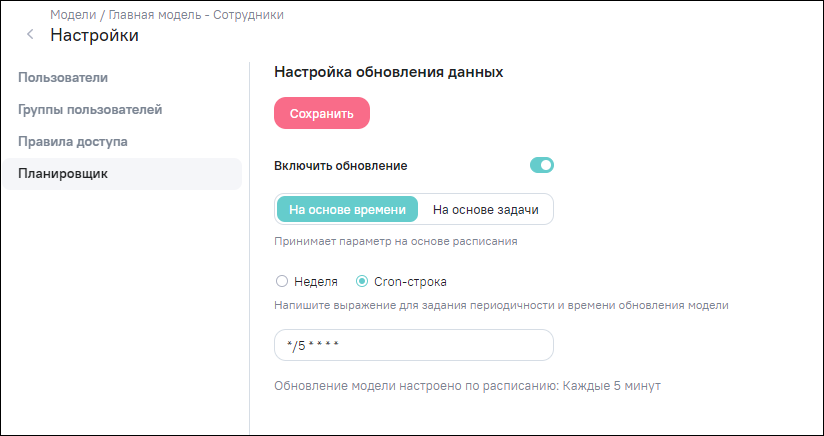
В режиме «Cron–строка» можно реализовать и более сложные режимы обновления, преодолевающие описанные ограничения за счет прямого ввода cron-строки в формате файла linux CRONTAB в соответствии с принятыми правилами ее написания. При вводе cron-выражения под полем ввода отобразится описание настроенного расписания. Например, на рисунке (Рисунок «Настроенное расписание на основе времени в режиме «Cron-строка») обновление модели настроено с периодичностью каждые 5 минут.
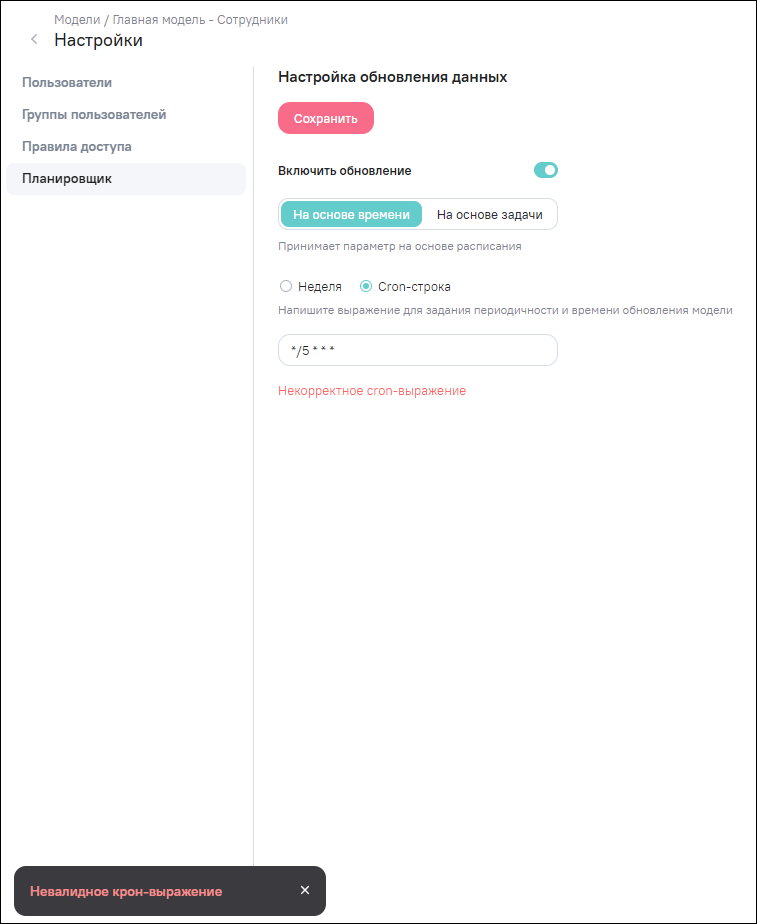
В случае ввода некорректного cron-выражения под полем ввода отобразится подсказка красного цвета «Некорректное cron-выражение». При сохранении некорректного выражения cron-строки отобразится уведомление об ошибке (Рисунок «Уведомление об ошибке при сохранении некорректного выражения cron-строки»).
Чтобы сохранить и применить изменения, нажмите на кнопку «Сохранить».
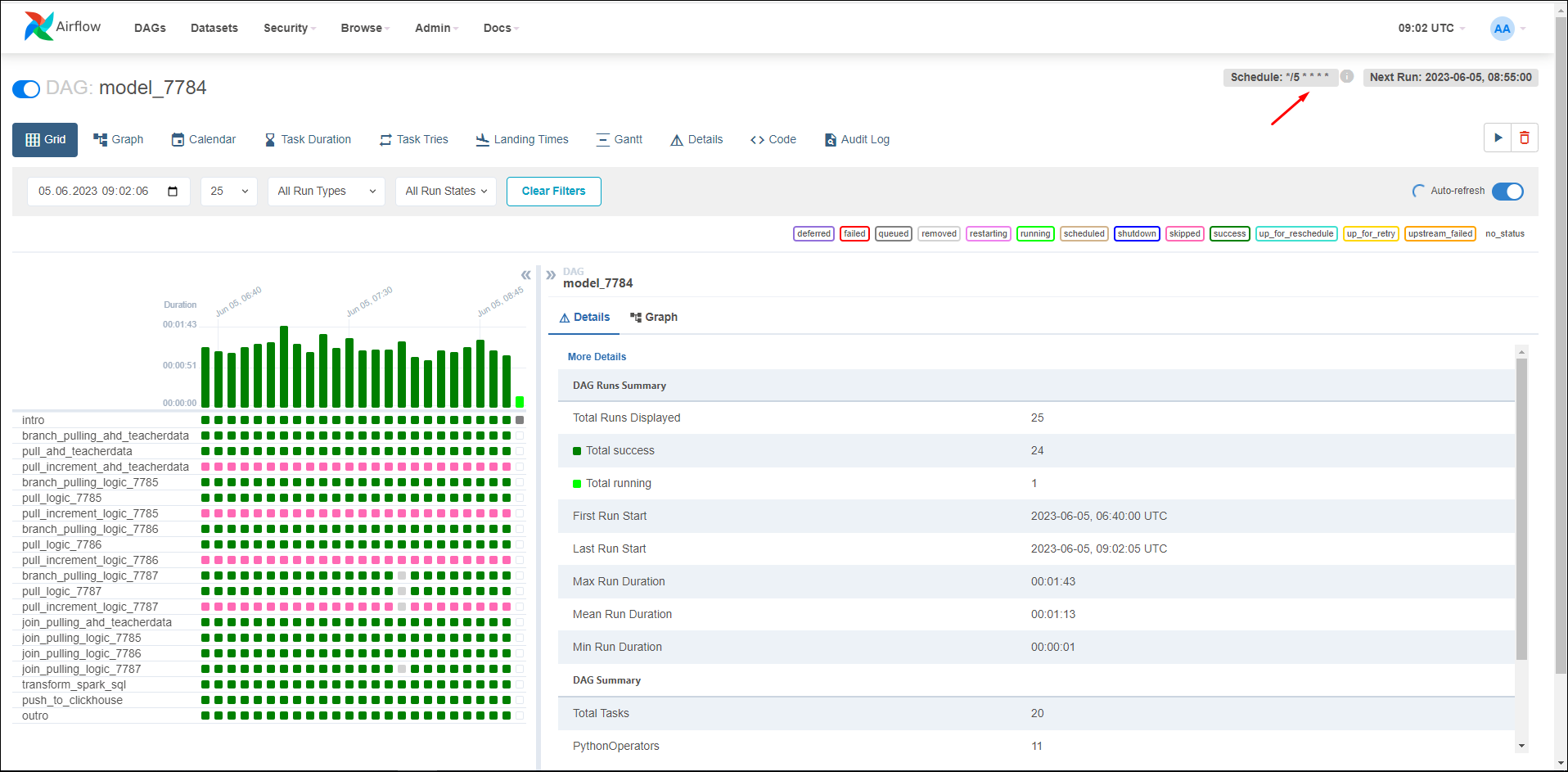
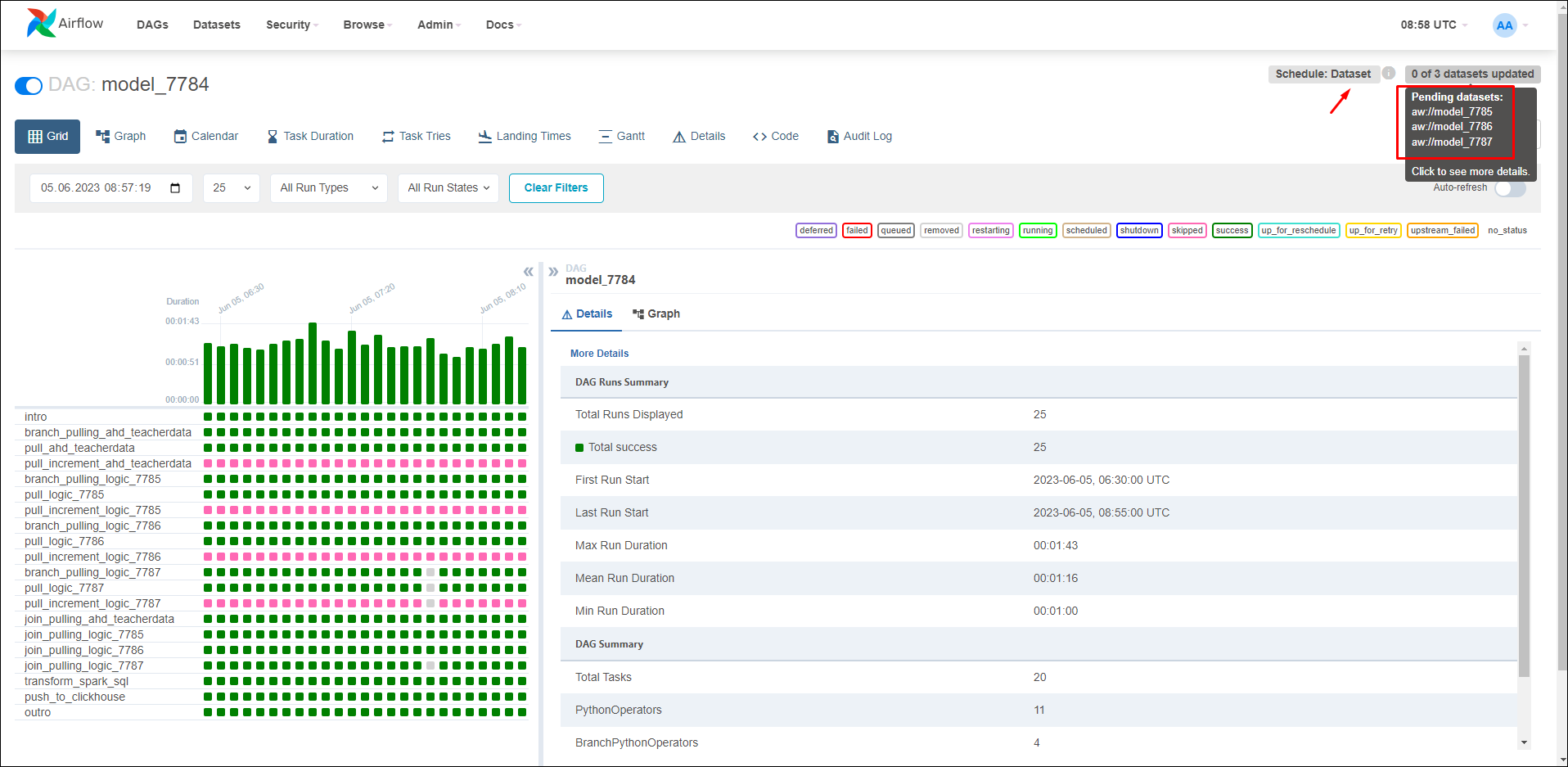
В Apache Airflow в правом углу DAG модели отображается настроенное расписание в виде cron-строки (Рисунок «Настроенное расписание на основе времени в режиме «Cron–строка», Рисунок «Отображение настроенного расписания в виде cron-строки в Apache Airflow»).
В разделе «Планировщик» выберите вариант настройки «На основе задачи» (см. Рисунок «Раздел «Планировщик», вариант настройки «На основе задачи»).
Принцип работы обновления модели при данном варианте заключается в следующем:
-
планирование запуска: текущая модель может быть помечена как зависимая от других моделей – из числа тех, которые используются в текущей. Завершение синхронизации выбранных моделей будет служить сигналом к запуску синхронизации текущей модели;
-
условия запуска: зависимость одной модели от других строится на основе построения связей между ними через наборы данных, производимых и потребляемых соответствующими этим моделям DAG-конвейерами. В данном случае процесс синхронизации модели рассматривается как задача конвейерной обработки модели по схеме, определяемой в DAG. Результатом исполнения DAG является набор данных, сопоставленный данной модели. Набор данных будет помечен как обновленный только в том случае, если задача завершится успешно. Если же задача завершится ошибкой или если она будет пропущена, обновление набора данных не произойдет и зависимый DAG не будет запланирован;
-
старт запуска: если один набор данных обновляется несколько раз до того, как будут обновлены все потребляемые наборы данных, зависимый DAG все равно будет запущен только один раз.
Для настройки планировщика на основе задачи выберете хотя бы одну модель из предложенного списка моделей, которые используются в текущей. Чтобы сохранить и применить изменения, нажмите на кнопку «Сохранить».
Если ни одна модель выбрана не будет, то при сохранении откроется уведомление об ошибке (Рисунок «Уведомление об обязательном выборе модели»).
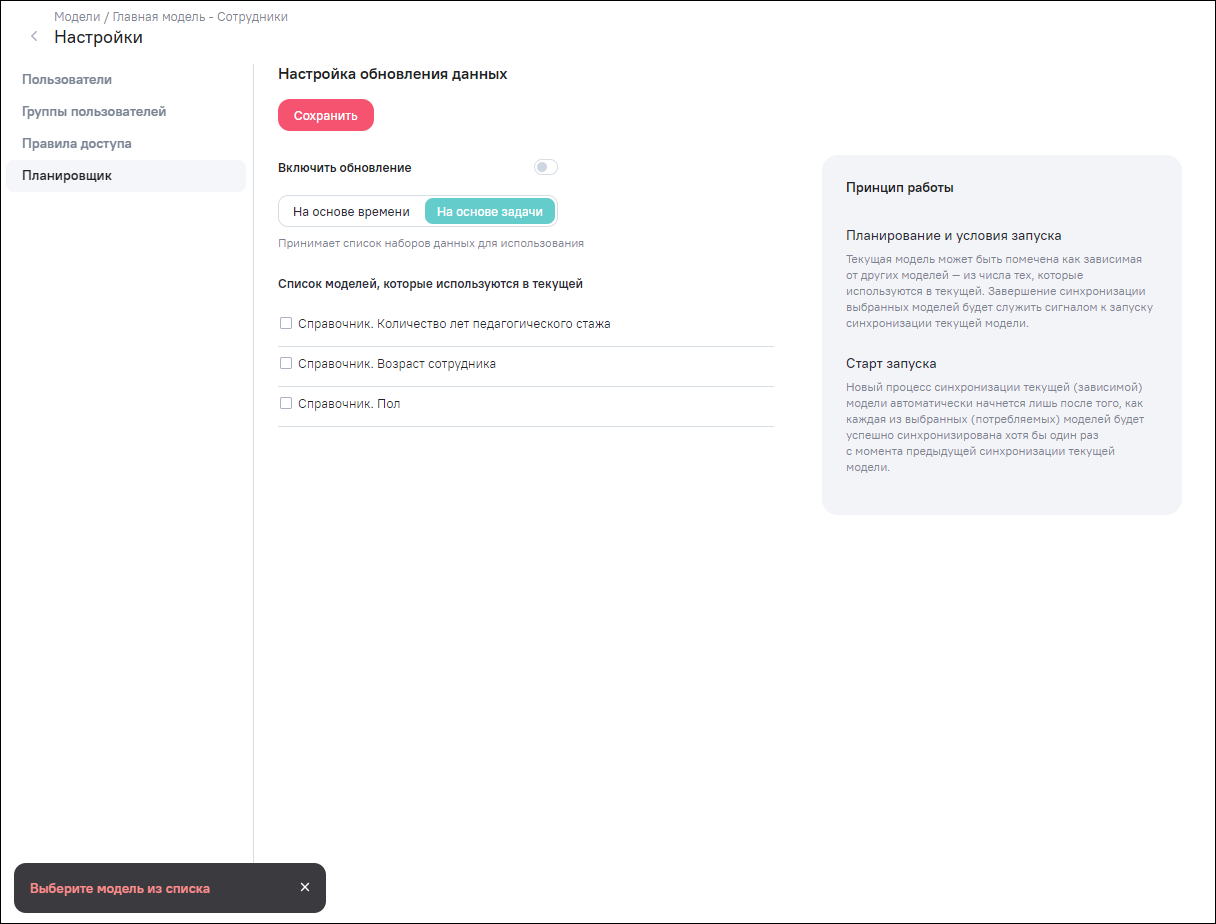
Если в схеме модели не участвуют другие модели, то список моделей в планировщике будет пуст. В этом случае при сохранении настроек откроется уведомление о необходимости использования планировщика на основе времени (Рисунок «Отображение пустого списка моделей. Уведомление о необходимости использования планировщика на основе времени»).
Рисунок 16. Отображение пустого списка моделей. Уведомление о необходимости использования планировщика на основе времени
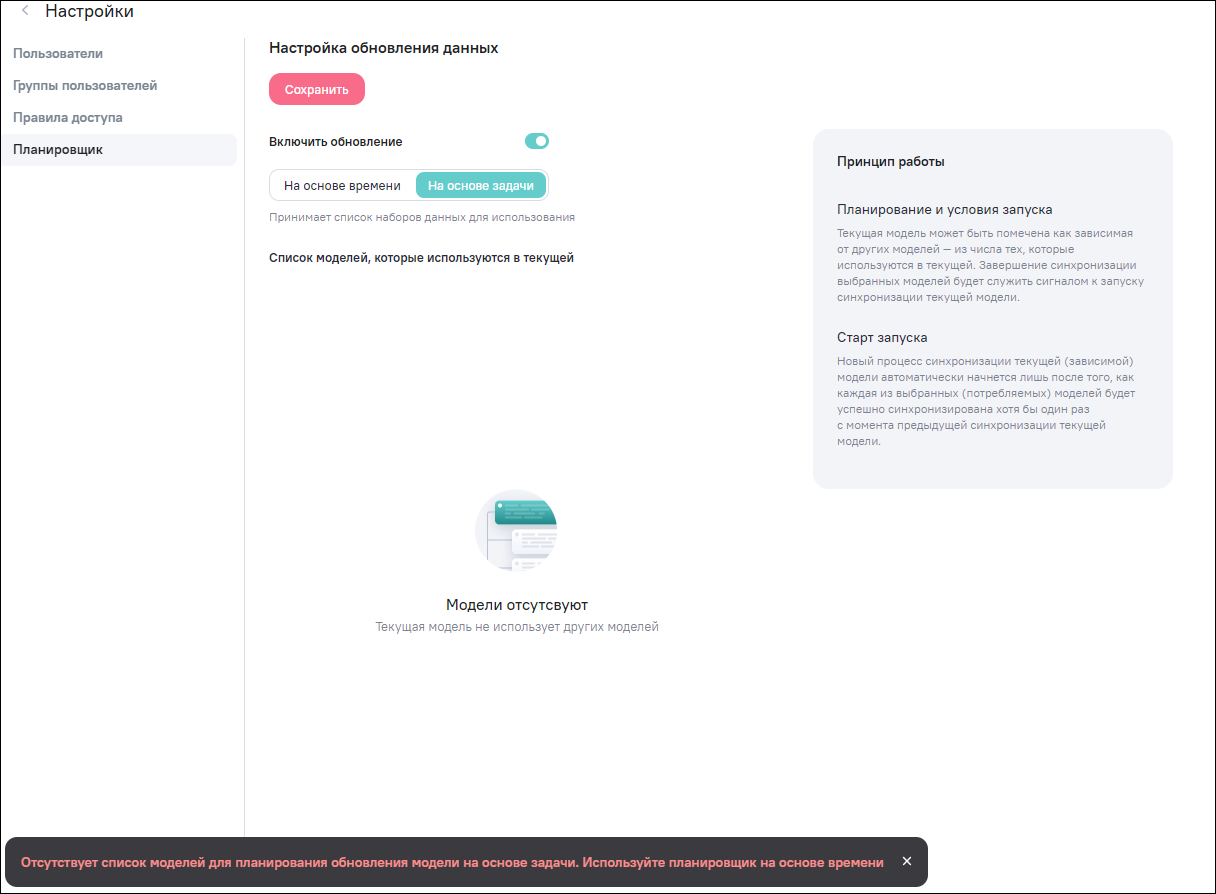
В Apache Airflow в правом углу DAG модели отображается метка Dataset и список моделей, от которых зависит запуск текущей модели (Рисунок «Отображение настроенного расписания на основе задачи в Apache Airflow»).
Настройка инкрементальной загрузки данных модели выполняется из интерфейса редактирования модели во вкладке «Инкрементальная загрузка». При добавлении блоков данных (таблицы, модели, SQL) на схему связей (Рисунок «Отображение блоков таблицы, модели, SQL на схеме связей») для каждого блока формируются отдельные фрагменты во вкладке «Инкрементальная загрузка» (Рисунок «Формирование фрагментов для каждого добавленного блока на схему связей»).
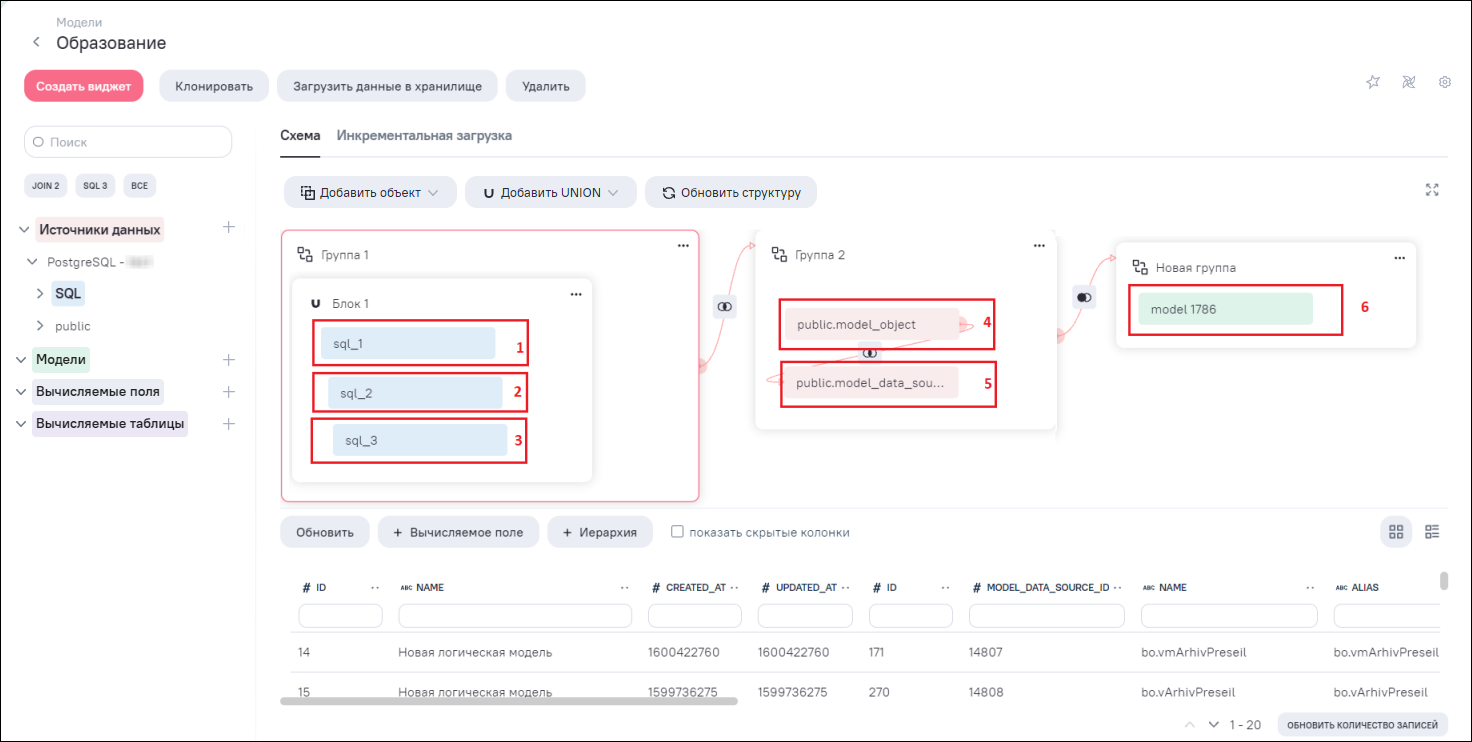
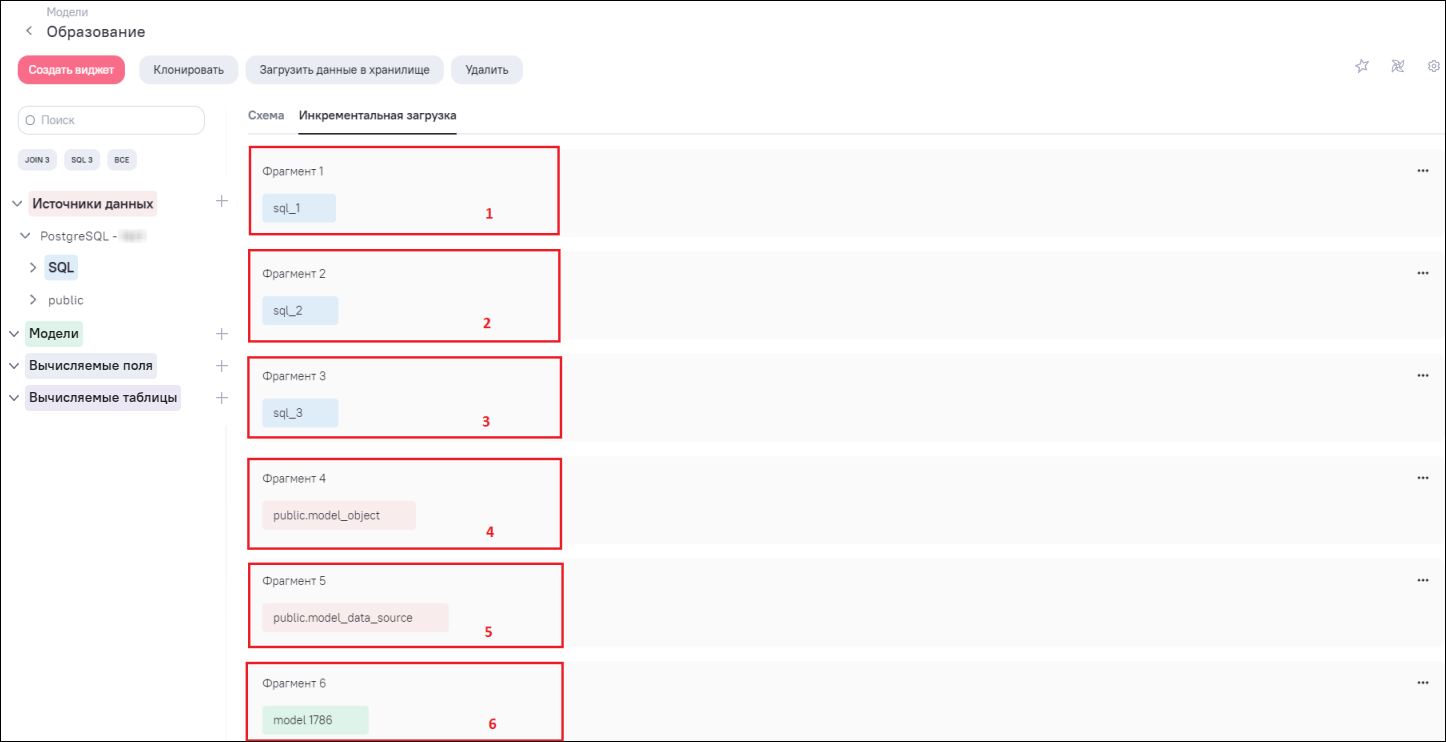
Фрагмент включает в себя:
-
номер фрагмента – фрагменты формируются в том порядке, в каком были добавлены блоки данных на схему связей. При удалении какого-либо блока на схеме связей номера фрагментов обновляются;
-
блок данных – отображается в таком же виде (соответствует цвет и наименование), как и на схеме связей (см. Рисунок «Отображение блоков таблицы, модели, SQL на схеме связей», Рисунок «Формирование фрагментов для каждого добавленного блока на схему связей»);
-
дополнительное меню
 – отображается напротив каждого фрагмента. При нажатии кнопку
меню отобразится кнопка «Настройка»
– отображается напротив каждого фрагмента. При нажатии кнопку
меню отобразится кнопка «Настройка»  . При нажатии на кнопку «Настройка» будет выполнен переход к
окну настроек инкрементальной загрузки данных.
. При нажатии на кнопку «Настройка» будет выполнен переход к
окну настроек инкрементальной загрузки данных.
 Примечание Примечание
|
|---|
| Инкрементальная загрузка игнорируется для фрагментов, источником которых является файл. Независимо от настройки будет выполняться полная выгрузка данных. |
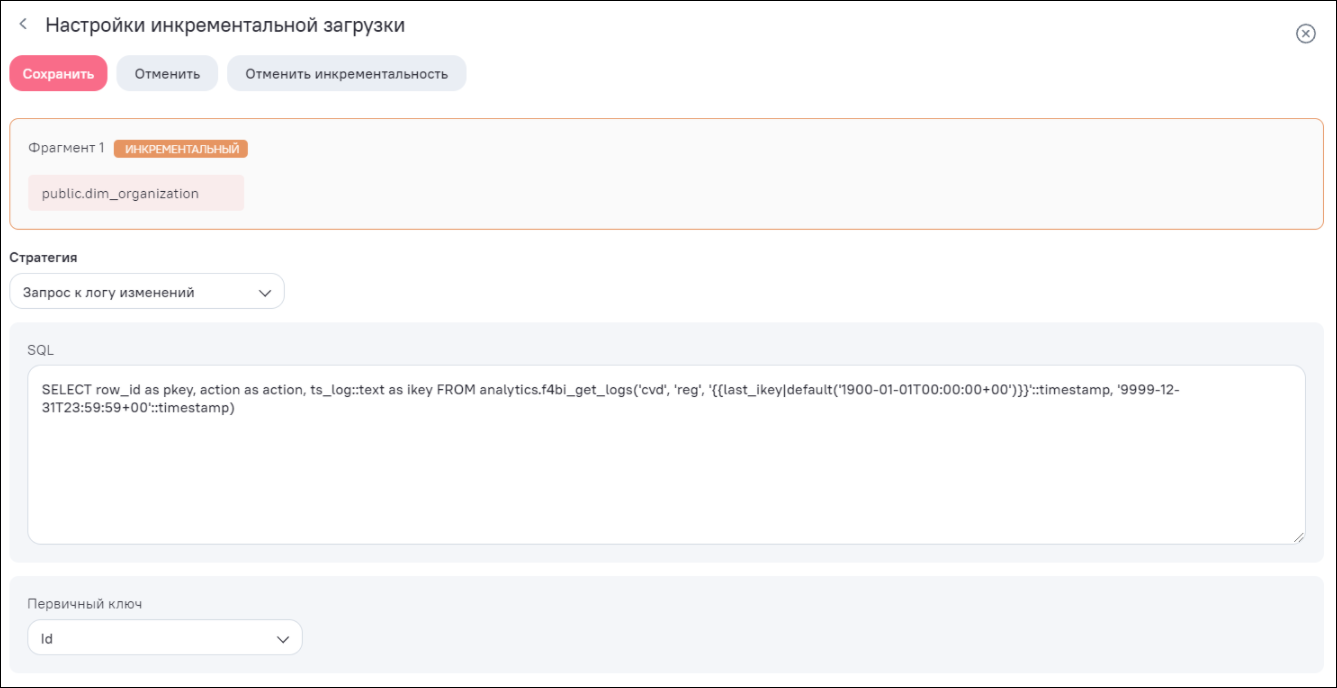
Окно настройки инкрементальной загрузки по стратегии «Запрос к логу изменений» данных содержит следующие элементы (Рисунок «Окно настройки инкрементальной загрузки данных по стратегии «Запрос к логу изменений»):
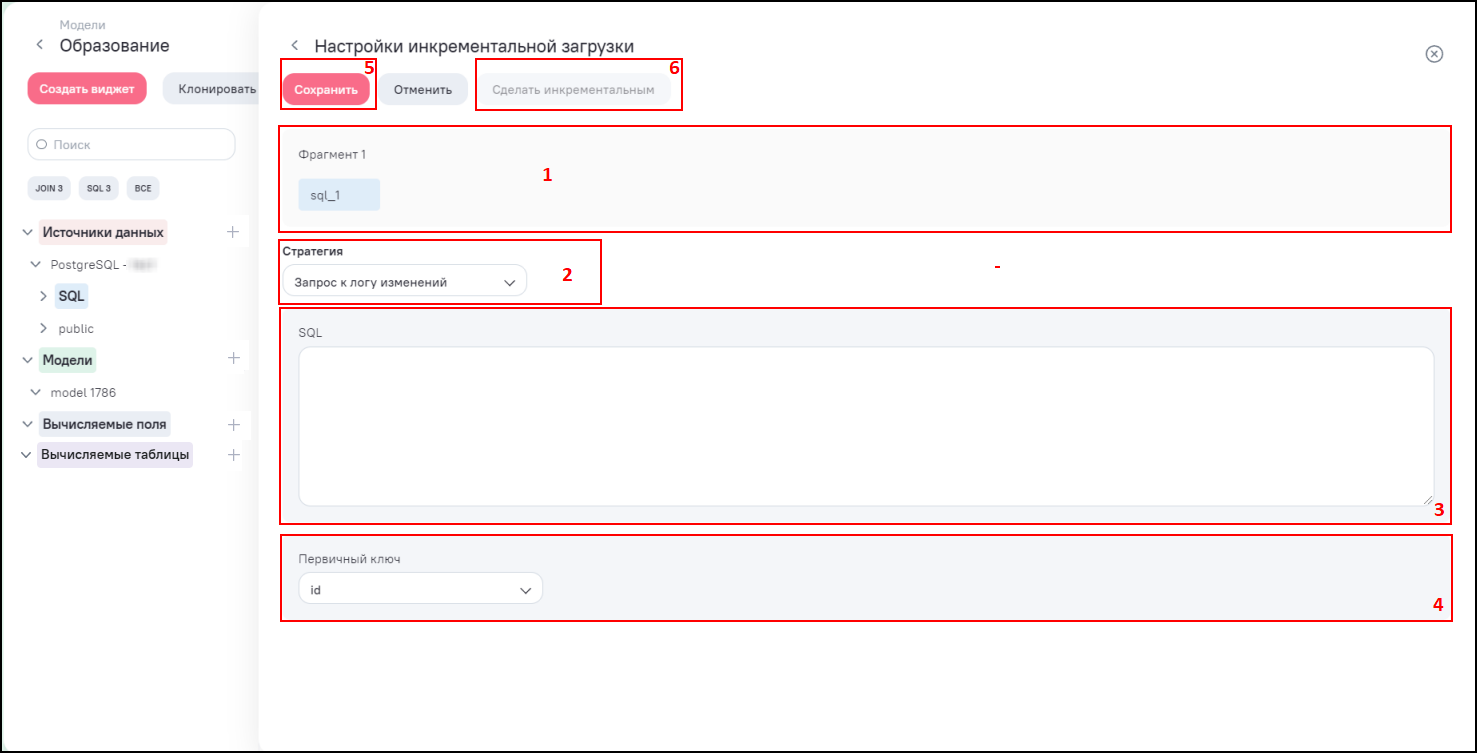
-
блок фрагмента (1);
-
поле «Стратегия» для выбора типа стратегии из выпадающего списка (2). Доступные значения:
-
«Запрос к логу изменений»;
-
«Стандартная».
-
-
при выборе типа стратегии «Запрос к логу изменений» доступны следующие настройки:
-
поле «SQL» для обращения к таблице логов (3);
Примечание
Для удобства настройки в поле ввода SQL-скрипта при вводе первых букв отображаются значения справочников (IntelliSense) и подсветка синтаксиса. Справочники реализованы по полям модели, ключевым словам (select, from и др.), алиасам (при выборе алиаса в выпадающем списке в формуле указывается код выбранного поля для корректной работы запроса), таблицам (при выборе листов или таблиц файловых источников в выпадающем списке в запросе указывается его название в обратных кавычках ` ` для корректной работы запроса). -
поле «Первичный ключ» для выбора поля текущего фрагмента из выпадающего списка (4). Данный ключ необходим для распознавания строк, полученных после очередной итерации, но впоследствии измененных в источнике.
-
-
кнопка «Сохранить» (5) – при нажатии на данную кнопку сохраняются настройки инкрементальной загрузки. По умолчанию фрагмент принимает тип «Абсолютный». Для смены типа нажмите на кнопку «Сделать инкрементальным» (6). Смена типа на «Инкрементальный» происходит сразу, и в карточке фрагмента отображается тип «Инкрементальный»
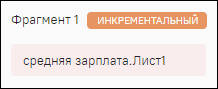 .
Примечание
.
Примечание
При клонировании модели копируются все фрагменты и их настройки, за исключением типа фрагмента «Инкрементальный».
Пример применения стратегии «Запрос к логу изменений» представлен на рисунке ниже (Рисунок «Пример функции для получения данных по стратегии «Запрос к логу изменений»).
Для получения логов по таблицам в SQL-запросе необходимо указать параметры. Параметры для приведенного на рисунке примера (см. Рисунок «Пример функции для получения данных по таблицам») указаны в поле «SQL», где:
-
analytics.f4bi_get_logs – наименование функции;
-
row_id as pkey, action as action, ts_log::text as ikey – выходные параметры, где:
-
row_id as pkey – ID записи, которая была изменена;
-
action as action – тип действия над записью;
-
ts_log – дата и время изменения записи.
-
-
('pers', 'person', '{{last_ikey|default('1900-01-01T00:00:00+00')}}'::timestamp, '9999-12-31T23:59:59+00'::timestamp) – входные параметры, где:
-
pers – схема таблицы БД;
-
person – таблица БД;
-
1900-01-01T00:00:00+00- дата и время начала периода;
-
9999-12-31T23:59:59+00 – дата и время окончания периода.
-
Принцип объединения в одной модели инкрементных и неинкрементных фрагментов:
-
неинкрементальные (абсолютные) фрагменты загружаются и обновляются полностью;
-
инкрементальный фрагмент загружается по принципу в зависимости от типа стратегии;
-
объединение данных происходит с полным набором данных как инкрементальных, так и абсолютных фрагментов в Spark.
Принцип загрузки инкрементального фрагмента с типом стратегии «Запрос к логу изменений»:
-
в Системе происходит запрос к источнику с помощью функции для получения логов по инкрементальному фрагменту;
-
источник возвращает идентификаторы записей, которые были изменены за запрашиваемый диапазон времени;
-
из источника используется текущий инкремент по объекту фрагмента;
-
в Системе обнаруживаются все ранее загруженные инкременты по этому фрагменту;
-
из доступных файлов (ранее загруженных и полученных при текущем запросе) формируется единый файл формата Apache Parquet по этому фрагменту, который будет обладать полным набором данных (т.е. формируется полная таблица с данными фрагмента);
-
полный набор данных по фрагменту передается в Spark, который выполняет все дальнейшие операции.
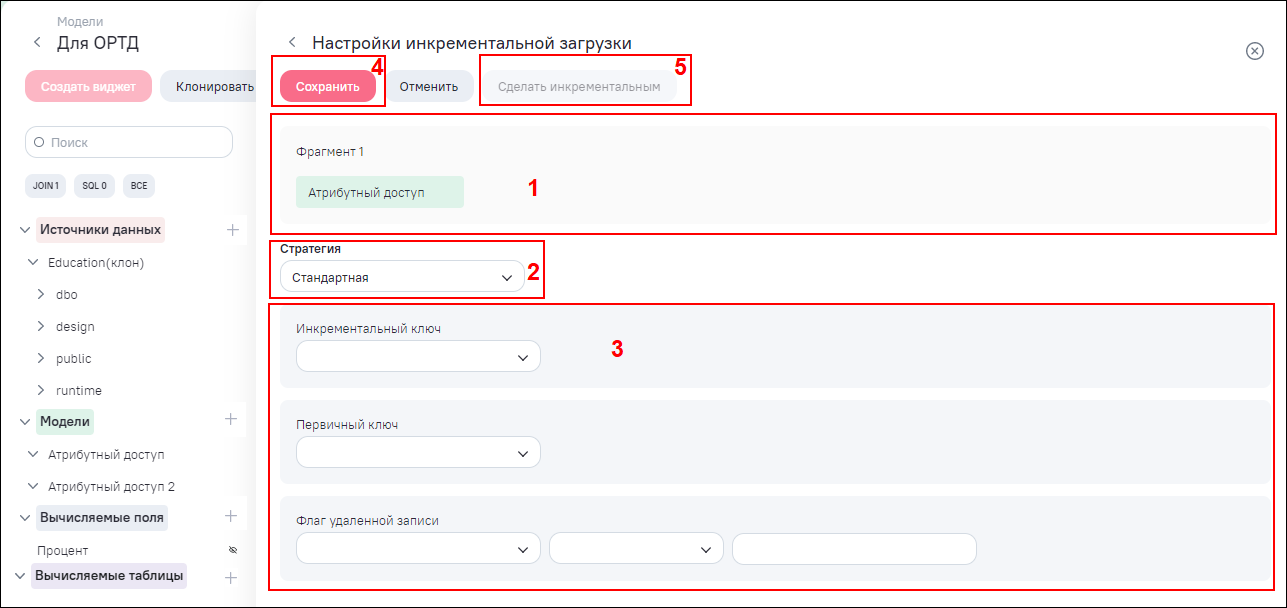
Окно настройки инкрементальной загрузки по стратегии «Стандартная» данных содержит следующие элементы (Рисунок «Окно настройки инкрементальной загрузки данных по стратегии «Стандартная»):
-
блок фрагмента (1);
-
поле «Стратегия» для выбора типа стратегии из выпадающего списка (2). Доступные значения:
-
«Запрос к логу изменений»;
-
«Стандартная».
-
-
при выборе типа стратегии «Стратегия» доступны следующие настройки (3):
-
поле «Инкрементальный ключ» для выбора поля текущего фрагмента. По выбранному ключу из источника в очередной сеанс синхронизации модели будут загружены все записи, значение IKEY которых будет больше максимального из ранее загруженного в Систему;
-
поле «Первичный ключ» для выбора поля текущего фрагмента. Данный ключ необходим для распознавания строк, полученных после очередной итерации, но впоследствии измененных в источнике;
-
поле «Флаг удаленной записи» для выбора поля текущего фрагмента. Задайте условие с помощью операторов условий. Данный ключ необходим для распознавания строк, полученных после очередной итерации, но впоследствии удаленных в источнике строками по заданному условию.
-
-
кнопка «Сохранить» (4) – при нажатии на данную кнопку сохраняются настройки инкрементальной загрузки. По умолчанию фрагмент принимает тип «Абсолютный». Для смены типа нажмите на кнопку «Сделать инкрементальным» (5). Смена типа на «Инкрементальный» происходит сразу, и в карточке фрагмента отображается тип «Инкрементальный»
.
Пример применения стратегии «Стандартная» представлен на рисунке ниже (Рисунок «Пример настройки для получения данных по стратегии «Стандартная»).
Принцип объединения в одной модели инкрементных и неинкрементных фрагментов:
-
неинкрементальные (абсолютные) фрагменты загружаются и обновляются полностью;
-
инкрементальный фрагмент загружается по принципу в зависимости от типа стратегии;
-
объединение данных происходит с полным набором данных как инкрементальных, так и абсолютных фрагментов в Spark.
Принцип загрузки инкрементального фрагмента с типом стратегии «Стандартная»:
-
первая загрузка при включенной инкрементальности: загружаются все данные источника, кроме данных, подходящих под условие, заданное в поле «Флаг удаленной записи». Также отрабатывается запрос на получение максимального значения поля с ключом инкрементальности для последующих запросов на получение инкремента.
-
последующая загрузка:
-
в Системе происходит запрос к источнику с помощью настроенных атрибутов инкрементального фрагмента (инкрементальный ключ, первичный ключ, условие в поле «Флаг удаленной записи»);
-
из источника загружается текущий инкремент по объекту фрагмента – все записи источника, у которых значение ключа инкрементальности больше или равно максимальному значению ключа из шага 1, исключая данные, подходящие под условие, заданное в поле «Флаг удаленной записи»;
-
в Системе обнаруживаются все ранее загруженные инкременты по этому фрагменту;
-
из доступных файлов (ранее загруженных и полученных при текущем запросе) формируется единый файл формата Apache Parquet по этому фрагменту, который будет обладать полным набором данных (т.е. формируется полная таблица с данными фрагмента);
-
полный набор данных по фрагменту передается в Spark, который выполняет все дальнейшие операции.
Примечание
Если при первичной загрузке модели не была включена инкрементальность, происходит полная загрузка (загружаются все данные), при которой не считываются удаленные записи. При последующих инкрементальных загрузках эти данные невозможно удалить в модели, т.к. их инкрементальный ключ будет меньше запрашиваемого максимального. Чтобы решить проблему, в виджете установите фильтр по полю, которое используется для определения удаленной строки (исключить удаленные строки). -